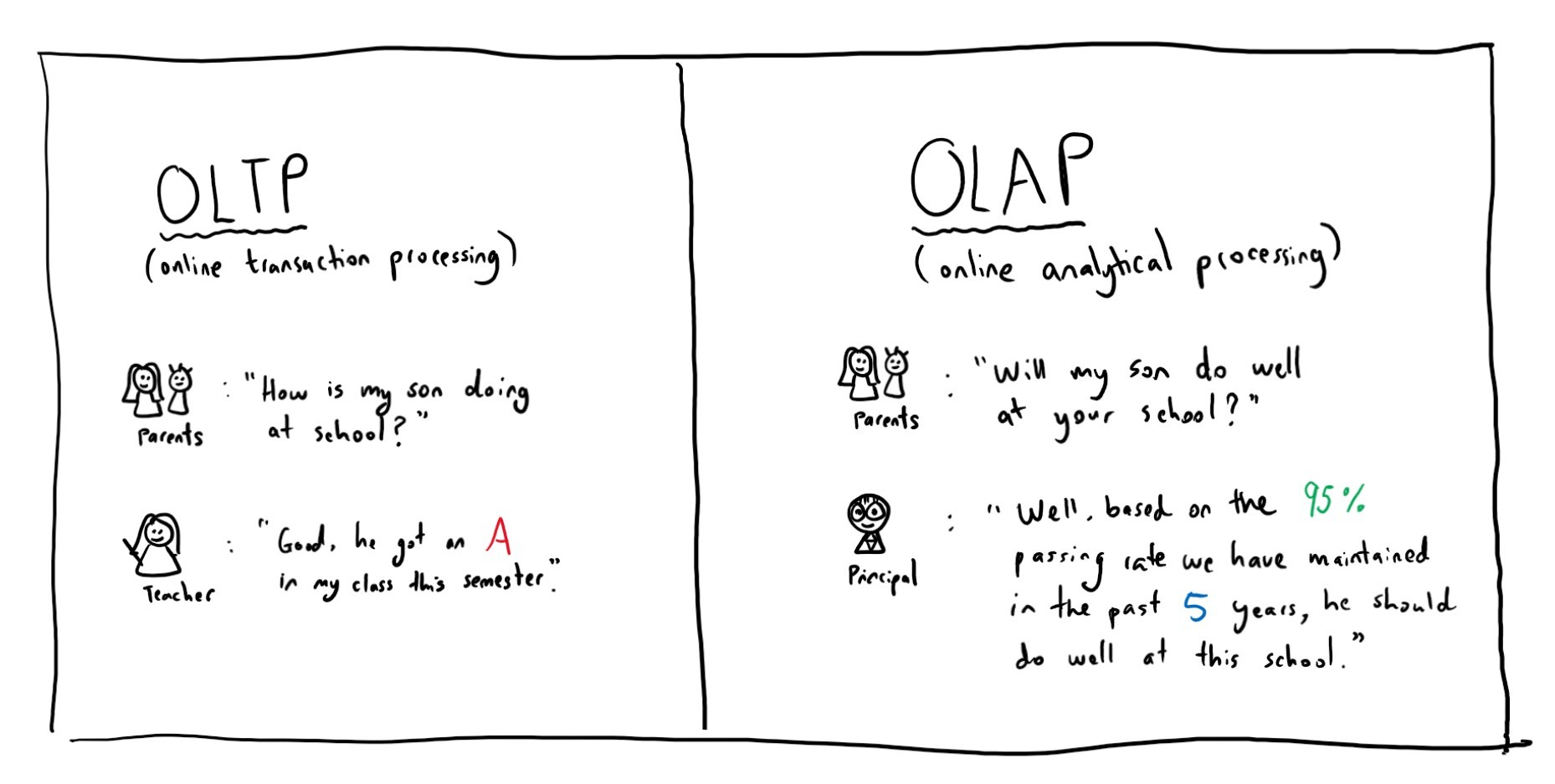
1980 년대 : OLTP, OLAP
- OLTP: on-Line transaction processing 온라인 거래 처리
- eg: 상품 주문, 회원정보 수정 , 은행이체
- 주컴퓨터와 통신 회성으로 접속하여 있는 복수 사용자의 단말에서 발생한 드랜잭션을 주 컴퓨터에서 처리하여 그결과를 사용자에게 되돌려주는 처리형태.
- OLAP: on-Line analytical Processing ,온라인 분석처리
-eg : 10년가 A사의 직급적 임금 상승률 <- not 1건의 거래에 대한 것
- 다차언으로 이루어진 데이터로부터 통계적인 요약 정보를 제공할수 있는 기술, 다차원 데이터를 대화식으로 분석하기 위한 소프트웨어
2000년대 CRM SCM
- CRM: customer Relationship Management
- 고객별 구매이력 데이터 베이스를 분석하고 고객에 대한 이해를 돕고 이를 바탕으로 각종 마케팅 전략을 동해 보다 높은 이익을 창출할수 있는 솔루션.
- SCM : supply chain Management
-제조,물류,유통업체 등 유통공급망에 참여하는 모든 업체들이 협력바탕으로 정보기술 을 활용, 재고의 최적화 하기 위한 솔루션.
-기업의 외부 공급체 또는 제츄 업체와 통합된 정보 시스템으로 연예하여 시간과 비용을 최적화 시키기위한것
-자재구매 데이터, 생산, 재고 데이터, 유통/판매 데이터, 고객 데이터로 구성
분야별 기업의 내부 데이터베이스 솔루션 : 제조 부분
- Data Warehouse
- 기업 내의 의사 결정 지원 application 을 위해 정보 제공하는 하나의 통합된 데이터 저장 공간
- ETL(extract, transform,load): 주기적인 내부 및 외부 데이터 베이스로 부터 정보를 추출하고 정해진 규약에 따라 정보를 변환 한 후에 정보를 적재함.
- 데이터들은 시간적 흐름에 따라 변화하는 값을 일정하게 유지
- Data warehouse 의 4대 특징
1. 데이터 통합 : 데이터들은 전사적인 차원에서 일관된 형식으로 정의
2. 데이터의 시계열성: 관리되는 데이터들은 시간의 흐름에 따라 변화 하는 값을 저장함.
3. 데이터의 주제지향적 : 특정 주제에 따라 데이터들을 분류 저장 관리됨 (분류하지만 따로 관리 하는것은 아니다, 분류해서 관리하는것은 Data Mart)
4. 비소멸성(비휘발성) : Batch 작업에 의해 생신외에 변하지 않음 (빈번한 삽입, 삭제아님)
- Datamart
- 전자적으로 구축된 데이터 웨어하우스로부터 특정 주제, 부서중심으로 구축된 소규모 단일주제의 데이터 웨어하우스.
- 재무, 생산, 운영과 같은 특정 조직의 특정업무 분야에 초점
- ERP
-Enterprise Resource Planning, 제조업을 포함한 다양한 비즈니스 분야에서 생산, 구매, 재고, 주문, 공급자와의 거래, 고객서비스 제공등 주요 프로세스관리를 돕는 여러 모듈로 구성된 통합된 application
- BI (business intelligence)
- 기업의 datawearhouse 에 저장된 데이터에 접근해 경영의사결정에 필요한 정보를 획득하고 이를 경영 활동에 활용하는것
-데이터를 통합분석하여 기업활동에 연관된 의사결정을 돕는 프로세스
-여러곳에 산재하여 있는 데이터를 수집하여 체계적이고 일목요연하게 정리하므로써 사용자가 필요하는 정보를 정확한 시간에 제공할수 있는 환경 by 가드너
- 하나의 특정 비즈니스 질문에 답변하도록 설계 <- 단위
- ad hoc report
- BI 와 빅데이터 분석의 차이점을 표현한 키워드,일회용으로 작성되는 임시 보고서 BI 도구를 사용하면 조직의 모든 가용자가 IT 직원에게 부담주지 않음 특정비지니스 질문에 답변 하고 해당 데이터를 시각적으로 표현할수 있으며 구조화된 보고서랑은 다르다.
- Optimization, forecast, insight : 빅데이터 키워드
- BA(business analytics)
-경영 의사 결정을 위해 통계적이고 수학적인 분석에 초점을 둔 기법
-성과에 대한 이해와 비지니스 동할력에 초점을 둔 분석 방법
-사전에 예측하고 최적화 하기위해 BI 보다 진보된 형태
분야별 기업의 내부 데이터베이스 솔루션 : 금융부분
- 블록체인(Block chain)
기존 금융회사의 중앙집중형 서버에 거래 기록을 보관 하는 방식에서 벗어나 거래에 참여하는 모든 사용자에게 거래의 내용을 보내주며 거래때 마다 이를 대조하는 데이터 위조 방지기술

분야별 기업의 내부 데이터베이스 솔루션 : 유통부분
- KMS (Knowledge Management system)
-조직 내의 지식을 체계적으로 관리 하는 시스템.
- RFID (RF, Radio Requency)
무선 주파수를 이용하여 대상을 식별하는 기술
-RF 태그에 사용 목적에 알맞은 정보를 저장 하여 저굥대상에 부탁한후 판독기에 해당 되는 RFID 디러를 통해 정보를 인식함
'Coming > ADsP' 카테고리의 다른 글
| ADsP 과목 1 : 데이터의 이해 (1) (1) | 2022.10.05 |
|---|---|
| 데이터 분석 기법의 이해 (0) | 2022.09.26 |