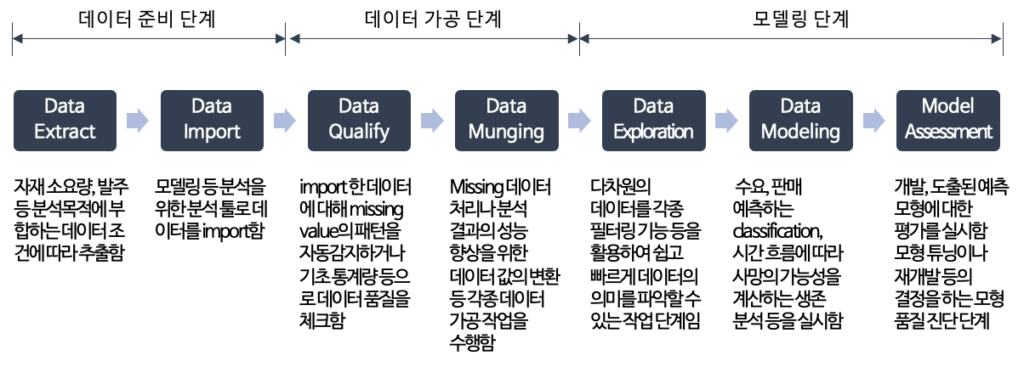
- 1. 데이터 처리

데이터를 위와 같이 활용 한다.
DW와 DW 를 통하여 분석 데이터를 가져와서 사용한다.
- ODS 는 운영데이터를 저장 하는 장소로 기존 운영 시스템(legacy) 의 데이터가 정제된 데이터 이므로 DM 나 DW 과 결합하여 분석을 활용 할수 있다. (시험에 나오는 문장으로 잘이해해야함)
- staging 영역(임시저장된 데이터) 에서 가져온 데이터는 정제되지 않은 데이터 이므로 데이터의 전처리를 하여 DW나 DM과 결합하여 사용한다.
- 2. 시각화 (시각화 그래프)
- 가장 낮은 수준의 분석 -> 복잡한 분석 보다 더 효율적으로 보여줌
- 대용량 데이터를 다루는 빅데이터 분석에서는-> 시각화 필수
- 탐색적 분석 -> 시각화 필수
- Social networ analsis (SNA) 분석을 할때 자주 사용 된다 (아래의 그림 참조)

- 3.GIS 공간분석(spatial analysis)
- 공간적 차원과 관련 속성을 시각화 하는 분석
- 지도 위에 관련 속성을 생성하고 크기, 모양, 선굵기, 색 등으로 구분

- ★4.탐색적 자로 분석 (EDA)
(1) 다양한 차원의 값을 조합 하여 특이한 점이나 의미 있는 사실을 도출하고 분석 의해 최종 목표를 달성해가는 과정
데이터의 특성이나 내재하는 구조적 관계를 알아야한다.
정의_summary
1.데이터 형태를 이해 2. 의미를 찾아내는 과정 ====> 자료를 직관적으로 바라보는 과정(시각화에 집중)
효율성을 확대하기 위해
a. 의미있는 변수의 집단과 아닌 집단을 구분 해야함 (필터를 통하여 eg. 1차2차,3차...)
300의 변수를 ----> 1차 100 (의미있는집단), 2차 50(의미있는집단), 150 (의미없는집단)
(2) EDA 의 4가지 주제
1. 저항성의 강조 : 수집된 자료의 결측값과 이상값이 있을때도 영향을 적게 받는 성질 (평균값 보다 중앙값을 선호)
2. 잔차의 계산: 잔차를 구해서 왜 보통값이랑 다른지? 주경향에서 벗어난 값이 왜 존재 하는가 ?
3. 자료변수의 재표현 : 원래 변수를 변환 -> 해석을 단순화 하기 위해서
4. 그래프를 통한 현시성 :시각적으로 표현
- 5. 데이터 마이닝
대용량의 자료로부터 정보를 요약하고 미래에 대한 예측을 목표로 하는 자료에 존재 하는 관계, 패턴, 규칙을 탐색하고 이를 모형화 함으로써 이전에 알려지지 않은 유용한 지식을 추축하는 분석방법.
데이터가 크고 정보가 다양할수록 활용하기 유리한 분석 방법이다.
Data mining의 5 stap
1 step 목적 정의 : 데이터 마이닝 도입 목적을 명확하게 함
2 step 데이터준비 : 데이터 정제(cleaning) 를 통해 데이터 품질 확보까지 포함( 데이터양을 충분히 확보)
3 step 데이터 가공 : 목적변수를 정의하고, 필요한 데이터를 데이터 마이닝소프트웨어에 적용할수있게 가공및 준비단계 ( 충분한 CPU와 메모리, 디스크 공간 등 개발 환경 구축이 선행)
4 step 데이터 마이닝 기법 적용 : 모델을 목적에 맞게 선택하고 소프트 웨어를 사용하는데 필요한 값 지정
5 step 검증 : 경과에 대한 검증 시행
데이터마이닝 관련 비지니스의 의사결정에 영향을 주는사례
--> 4 step 데이터 마이닝 기법 은 어떤 것들이 있을까 ?
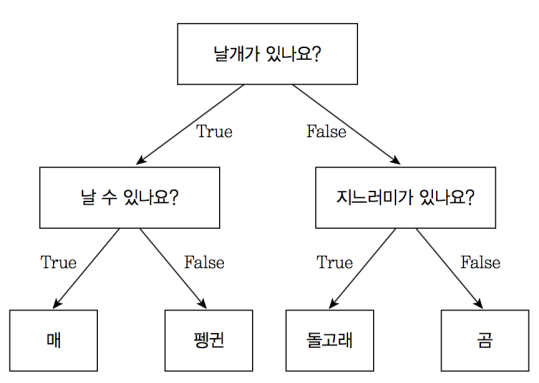
분류(classification) : 새롭게 나타나는 현상을 검토 하여 기존의 분류, 정의된 집합에 배정 하는것
의사나무 결정, Memory-based reasoning 등
추론(Estimation) : 주어진 입력데이터를 사용하여 알려지지 않은 결과 갓ㅂ을 추정 하는것
연속된 변수값을 추정, 신경망 모형
★연관분석(Association Analysis) : '같이 팔리는 물건' 같이 아이템의 연관성을 파악하는 분석
카탈로그 배열 및 교차 판매, 공격적 판촉행사 등의 마케팅 계획
eg 월마트에서 맥주와 기저귀가 강한 연관성 파악 -> 가까이 배치 -> 매출이 증가
예측(Prediction) : 미래에 대한 예측, 추정 하는것을 제외하면 분류나 추정과 동일한 의미
장바구니분석, 의사결정나무, 신경망모형
군집(Clustering): 미리 정의된 기준이나 예시에 의해서가 아닌 레코드 자체가 가진다른 레코드와의 유사성에 의해 그룹화되고 이질성에 의해 세분화됨(테이터마이닝이나 모델링의 준비단계로서 사용됨)
★기술(Description) : 데이터가 가진 특징 및 의미를 단순한 설명하는것
데이터가 암시하는 바에 대해 설명 및 그에대한 답을 찾아 낼수 있어야함
'Coming > ADsP' 카테고리의 다른 글
| ADsp 과목 1 :기업 내부 DB (1) | 2022.10.05 |
|---|---|
| ADsP 과목 1 : 데이터의 이해 (1) (1) | 2022.10.05 |